

In questa lezione descriviamo come utilizzare il Natural Language Processing per il Trading, una tecnica di apprendimento supervisionato applicato alla classificazione dei documenti. L’obiettivo è realizzare l’analisi del sentiment e, in definitiva, costruire un filtro per il trading automatico o per generare segnali operativi. A tale scopo utilizziamo le Support Vector Machines (SVM), introdotte nella lezione precedente, per classificare documenti testuali in gruppi che si escludono a vicenda.
Natural Language Processing per il Trading
Affrontiamo numerosi passaggi fondamentali per passare dalla semplice visualizzazione di un documento testuale su un sito web, per esempio, all’utilizzo del suo contenuto come input in una strategia di trading automatica, utile per generare segnali o filtri. In particolare, svolgiamo le seguenti attività:
- Automatizziamo il download continuo di articoli generati da fonti esterne, mantenendo una velocità di esecuzione elevata.
- Analizziamo le sezioni di testo e le informazioni rilevanti contenute nei documenti, anche quando presentano formati differenti.
- Convertiamo paragrafi di testo, anche molto lunghi e in diverse lingue, in una struttura dati coerente comprensibile da un sistema di classificazione.
- Stabiliamo un insieme di gruppi (o etichette) nei quali inseriamo ogni documento, ad esempio “positivo” e “negativo” oppure “rialzista” e “ribassista”.
- Creiamo un “training corpus” composto da documenti con etichette note; per esempio, etichettiamo mille articoli finanziari come “rialzista” o “ribassista”.
- Addestriamo i classificatori su questo corpus utilizzando una libreria software come scikit-learn di Python, che impieghiamo nelle prossime sezioni.
- Applichiamo il classificatore per etichettare automaticamente e in modo continuo nuovi documenti.
- Valutiamo il “tasso di classificazione” e altre metriche di performance associate al classificatore.
- Integriamo il classificatore in un sistema di trading automatico per filtrare altri segnali o generarne di nuovi.
- Monitoriamo costantemente il sistema e lo regoliamo quando le sue prestazioni iniziano a diminuire.
In questa lezione scegliamo di non spiegare come scarichiamo articoli da diverse fonti esterne e utilizziamo invece un dataset precompilato, già etichettato. Così possiamo concentrarci sull’attuazione del natural language processing nella “pipeline di classificazione”, senza dedicare troppo tempo alla raccolta e all’etichettatura dei documenti.
Approcci e metodi
Possiamo utilizzare le librerie Python come Scrapy e BeautifulSoup per ottenere automaticamente numerosi articoli dal web ed estrarre in modo efficace i dati testuali contenuti nell’HTML.
Inoltre, in questa lezione non trattiamo l’integrazione di un classificatore all’interno di un sistema di trading algoritmico pronto per l’uso in produzione. Tuttavia, approfondiremo questo aspetto nelle lezioni successive.
Riteniamo estremamente importante non solo costruire esempi didattici, ma anche affrontare l’integrazione completa del natural language processing in un sistema realmente utilizzabile in produzione. E’ fondamentale quindi prevedere anche l’implementazione all’interno di un sistema reale.
Supponiamo di avere già a disposizione un corpus pre-etichettato (che descriveremo tra poco!) e iniziamo caricando il training corpus in una struttura dati Python adatta alla fase di pre-elaborazione e all’uso tramite il classificatore.
Prima però di entrare nei dettagli di questo processo di apprendimento supervisionato, dedichiamo qualche riga alla spiegazione dei concetti di classificazione supervisionata e di macchine vettoriali di supporto.
Classificazione supervisionata e Macchine Vettoriali di Supporto
Per un approfondimento sui concetti fondamentali dell’apprendimento automatico statistico, consigliamo di consultare questa lezione.
Classificatori Supervisionati
I classificatori supervisionati comprendono un insieme di tecniche di apprendimento automatico statistico che associano una “classe” o “etichetta” a uno specifico insieme di funzionalità, utilizzando etichette già note collegate ad altri set di features simili.
Questa definizione può sembrare astratta, quindi ricorriamo a un esempio concreto. Immaginiamo di analizzare una serie di documenti di testo. Ogni documento include un insieme di parole, che definiamo “features” o caratteristiche. Colleghiamo poi ciascun documento a un’etichetta che descrive l’argomento della lezione.
Supponiamo di avere una raccolta di lezioni online sugli animali domestici: alcune trattano principalmente di cani, altre di gatti o criceti. Parole come “gabbia” (criceto), “guinzaglio” (cane) o “latte” (gatto) risultano più indicative di alcuni animali rispetto ad altri. Utilizzando documenti di addestramento già etichettati manualmente, possiamo far apprendere ai classificatori supervisionati quali parole rappresentano meglio ciascuna etichetta (animale).
In termini matematici, associamo ciascuna delle \(j\) lezioni sugli animali a un vettore \(j\) di features, in cui ogni componente misura la “forza” di una parola (definiremo il concetto di “forza” più avanti). Associamo poi a ogni documento un’etichetta di classe, \(j\), che indica l’animale più rappresentativo del contenuto.
Prevediamo l’apprendimento supervisionato durante l’addestramento quando adattiamo un modello ai dati etichettati. A tale scopo usiamo Support Vector Machine come modello e le addestriamo su un corpus (una raccolta di documenti) già predisposto.
Support Vector Machines
Per una panoramica matematica completa sul funzionamento delle Support Vector Machines, invitiamo a leggere questa lezione.
Le Support Vector Machine (SVM) rappresentano una categoria di classificatori supervisionati che suddividono uno spazio in due o più gruppi, ovvero separano una raccolta di lezioni in differenti etichette di classe.
Per ottenere questa separazione, le SVM identificano il miglior confine possibile basandosi sulle etichette di classe già note. Nei casi più semplici, questo “confine” è lineare e suddivide i gruppi mediante linee (o piani) in spazi multidimensionali.
Quando le etichette non risultano ben separabili con confini lineari, ricorriamo a partizioni non lineari usando un metodo kernel. Questo approccio rende le SVM modelli molto sofisticati e potenti, anche se comportano il rischio di overfitting, sempre presente nell’apprendimento supervisionato
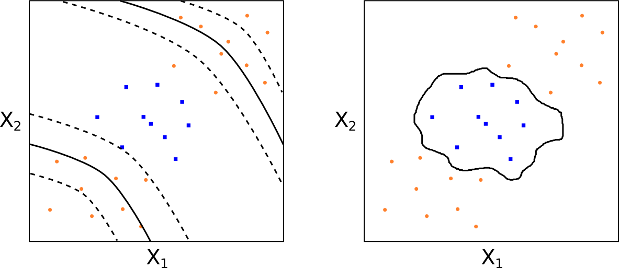
Nella figura seguente mostriamo due esempi di limiti decisionali non lineari (kernel polinomiale e radiale) per due etichette di classe (arancione e blu), rappresentate attraverso due features [label]X_1[/label] e [label]X_2[/label].
Gli SVM, se utilizzati con competenza, offrono risultati estremamente promettenti. Per il resto di questa lezione, continueremo a lavorare con le Support Vector Machine.
Preparare un Dataset per la Classificazione
Uno dei dataset più noti per progettare classificatori in ambito di natural language processing è il Reuters 21578. Si tratta di uno dei dataset più usati nella classificazione del testo, anche se oggi appare leggermente datato. Tuttavia, per i nostri scopi nella presente lezione, risulta più che adatto.
Il dataset consiste in una raccolta di articoli giornalistici (un “corpus”) contrassegnati con argomenti e località geografiche. Questo lo rende immediatamente utilizzabile nei test di classificazione, dato che risulta già etichettato.
Download dei dati
Procediamo ora con il download, l’estrazione e la preparazione del dataset. Stiamo eseguendo il tutorial su una macchina Ubuntu 18.04, quindi lavoriamo tramite terminale. Se utilizzi Linux o Mac OSX, puoi seguire gli stessi comandi. Con Windows, invece, dovrai procurarti uno strumento per l’estrazione dei file Tar/GZIP.
Scarichiamo il dataset Reuters 21578 da questo link, in formato compresso tar GZIP. Come primo passo, creiamo una nuova directory di lavoro e salviamo il file al suo interno. Puoi naturalmente assegnare alla directory il nome che preferisci.
cd ~
mkdir -p tradingquant/classification/data
cd tradingquant/classification/data
wget http://kdd.ics.uci.edu/databases/reuters21578/reuters21578.tar.gz
tar -zxvf reuters21578.tar.gz
... 186 Dec 4 1996 all-exchanges-strings.lc.txt
... 316 Dec 4 1996 all-orgs-strings.lc.txt
... 2474 Dec 4 1996 all-people-strings.lc.txt
... 1721 Dec 4 1996 all-places-strings.lc.txt
... 1005 Dec 4 1996 all-topics-strings.lc.txt
... 28194 Dec 4 1996 cat-descriptions_120396.txt
... 273802 Dec 10 1996 feldman-cia-worldfactbook-data.txt
... 1485 Jan 23 1997 lewis.dtd
... 36388 Sep 26 1997 README.txt
... 1324350 Dec 4 1996 reut2-000.sgm
... 1254440 Dec 4 1996 reut2-001.sgm
... 1217495 Dec 4 1996 reut2-002.sgm
... 1298721 Dec 4 1996 reut2-003.sgm
... 1321623 Dec 4 1996 reut2-004.sgm
... 1388644 Dec 4 1996 reut2-005.sgm
... 1254765 Dec 4 1996 reut2-006.sgm
... 1256772 Dec 4 1996 reut2-007.sgm
... 1410117 Dec 4 1996 reut2-008.sgm
... 1338903 Dec 4 1996 reut2-009.sgm
... 1371071 Dec 4 1996 reut2-010.sgm
... 1304117 Dec 4 1996 reut2-011.sgm
... 1323584 Dec 4 1996 reut2-012.sgm
... 1129687 Dec 4 1996 reut2-013.sgm
... 1128671 Dec 4 1996 reut2-014.sgm
... 1258665 Dec 4 1996 reut2-015.sgm
... 1316417 Dec 4 1996 reut2-016.sgm
... 1546911 Dec 4 1996 reut2-017.sgm
... 1258819 Dec 4 1996 reut2-018.sgm
... 1261780 Dec 4 1996 reut2-019.sgm
... 1049566 Dec 4 1996 reut2-020.sgm
... 621648 Dec 4 1996 reut2-021.sgm
... 8150596 Mar 12 1999 reuters21578.tar.gz
Vediamo che tutti i file che iniziano con reut2- sono .sgm, il che significa che sono file SGML. Sfortunatamente, Python ha deprecato sgmllib a partire da Python 2.6 e lo ha completamente rimosso in Python 3. Tuttavia, non tutto è perduto perché possiamo creare la nostra classe SGML Parser che sovrascrive quella HTMLParser incorporata in Python.
Analisi del Dataset
Ecco un singolo elemento presente in uno dei file:
Sebbene possa essere alquanto laborioso analizzare i dati in questo modo, specialmente se confrontati con l’effettivo apprendimento automatico, posso assicurarti che gran parte della giornata di un data scientist o di un ricercatore quantistico consiste nell’ottenere effettivamente i dati in un formato utilizzabile dai software di analisi! Questa particolare attività viene spesso chiamata scherzosamente “data wrangling”. Quindi è opportuno fare un po ‘di pratica!
Se diamo un’occhiata al file topics, all-topics-strings.lc.txt, digitando less all-topics-strings.lc.tx possiamo vedere quanto segue (per sintesi ne ho rimosso la maggior parte):
acq
alum
austdlr
austral
barley
bfr
bop
can
carcass
castor-meal
castor-oil
castorseed
citruspulp
cocoa
coconut
coconut-oil
coffee
copper
copra-cake
corn
...
...
silver
singdlr
skr
sorghum
soy-meal
soy-oil
soybean
stg
strategic-metal
sugar
sun-meal
sun-oil
sunseed
tapioca
tea
tin
trade
tung
tung-oil
veg-oil
wheat
wool
wpi
yen
zinc
Eseguendo il comando cat all-topics-strings.lc.txt | wc -l possiamo vedere che ci sono 135 argomenti separati tra gli articoli. Ciò rappresenterà la vera sfida del natural language processing!
Coppie predittore-risposta
In questa fase dobbiamo creare quello che è noto come un elenco di coppie predittore-risposta. Questo è un elenco di due tuple che contengono l’etichetta di classe più appropriata e il testo del documento non elaborato, come due componenti separati. Ad esempio, l’obbiettivo dell’analisi è ottenere una struttura dati simile alla seguente:
[
("cat", "It is best not to give them too much milk"),
("dog", "Last night we took him for a walk, but he had to remain on the leash"),
..
..
("hamster", "Today we cleaned out the cage and prepared the sawdust"),
("cat", "Kittens require a lot of attention in the first few months")
]
Per creare questa struttura è necessario analizzare individualmente tutti i file Reuters e aggiungerli a un grande elenco di “corpus”. Poiché la dimensione del file del corpus è piuttosto bassa, si adatterà facilmente alla RAM disponibile sulla maggior parte dei laptop / desktop moderni.
Tuttavia, nelle applicazioni in produzione è solitamente necessario trasmettere i dati di addestramento in un sistema di apprendimento automatico ed eseguire un “adattamento parziale” su ciascun lotto, in modo iterativo. Questo scenario è applicato con set di dati estremamente grandi (in particolare i dati tick).
Parsing dei dati
Come affermato in precedenza, il nostro primo obiettivo è creare l’SGML Parser che raggiunga effettivamente questo obiettivo. Per fare ciò, ereditiamo la classe HTMLParser di Python per gestire i specifici tag nel set di dati Reuters.
Quando si eridita la classe HTMLParser, dobbiamo sovrascrivere tre metodi, handle_starttag, handle_endtag e handle_data, che dicono al parser cosa fare all’inizio dei tag SGML, cosa fare alla chiusura dei tag SGML e come gestire i dati intermedi.
Creiamo anche due metodi aggiuntivi, _reset e parse, che vengono utilizzati per monitorare lo stato interno della classe e per analizzare i dati effettivi in modo frammentato, in modo da non utilizzare troppa memoria.
Infine, implementiamo una elementare funzione __main__ di per testare il parser sul primo set di dati all’interno del corpus Reuters.
Come per la maggior parte, se non tutti, dei codici presenti su TradingQuant, ho inserito commenti parlanti in modo che si possa capire cosa si sta implementando ad ogni passaggio:
import html
import pprint
import re
from html.parser import HTMLParser
class ReutersParser(HTMLParser):
"""
ReutersParser è una sottoclasse HTMLParser e viene utilizzato per aprire file SGML
associati al dataset di Reuters-21578.
Il parser è un generatore e produrrà un singolo documento alla volta.
Poiché i dati verranno suddivisi in blocchi durante l'analisi, è necessario mantenere
alcuni stati interni di quando i tag sono stati "inseriti" e "eliminati".
Da qui le variabili booleani in_body, in_topics e in_topic_d.
"""
def __init__(self, encoding='latin-1'):
"""
Inizializzo la superclasse (HTMLParser) e imposto il parser.
Imposto la decodifica dei file SGML con latin-1 come default.
"""
html.parser.HTMLParser.__init__(self)
self._reset()
self.encoding = encoding
def _reset(self):
"""
Viene chiamata solo durante l'inizializzazione della classe parser
e quando è stata generata una nuova tupla topic-body. Si
resetta tutto lo stato in modo che una nuova tupla possa essere
successivamente generato.
"""
self.in_body = False
self.in_topics = False
self.in_topic_d = False
self.body = ""
self.topics = []
self.topic_d = ""
def parse(self, fd):
"""
parse accetta un descrittore di file e carica i dati in blocchi
per ridurre al minimo l'utilizzo della memoria.
Quindi produce nuovi documenti man mano che vengono analizzati.
"""
self.docs = []
for chunk in fd:
self.feed(chunk.decode(self.encoding))
for doc in self.docs:
yield doc
self.docs = []
self.close()
def handle_starttag(self, tag, attrs):
"""
Questo metodo viene utilizzato per determinare cosa fare quando
il parser incontra un particolare tag di tipo "tag".
In questo caso, impostiamo semplicemente i valori booleani
interni su True se è stato trovato quel particolare tag.
"""
if tag == "reuters":
pass
elif tag == "body":
self.in_body = True
elif tag == "topics":
self.in_topics = True
elif tag == "d":
self.in_topic_d = True
def handle_endtag(self, tag):
"""
Questo metodo viene utilizzato per determinare cosa fare
quando il parser termina con un particolare tag di tipo "tag".
"""
if tag == "reuters":
self.body = re.sub(r'\s+', r' ', self.body)
self.docs.append((self.topics, self.body))
self._reset()
elif tag == "body":
self.in_body = False
elif tag == "topics":
self.in_topics = False
elif tag == "d":
self.in_topic_d = False
self.topics.append(self.topic_d)
self.topic_d = ""
def handle_data(self, data):
"""
I dati vengono semplicemente aggiunti allo stato appropriato
per quel particolare tag, fino a quando non viene visualizzato
il tag di chiusura finale.
"""
if self.in_body:
self.body += data
elif self.in_topic_d:
self.topic_d += data
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
filename = "data/reut2-000.sgm"
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
doc = parser.parse(open(filename, 'rb'))
pprint.pprint(list(doc))
..
..
(['grain', 'rice', 'thailand'],
'Thailand exported 84,960 tonnes of rice in the week ended February 24, '
'up from 80,498 the previous week, the Commerce Ministry said. It said '
'government and private exporters shipped 27,510 and 57,450 tonnes '
'respectively. Private exporters concluded advance weekly sales for '
'79,448 tonnes against 79,014 the previous week. Thailand exported '
'689,038 tonnes of rice between the beginning of January and February 24, '
'up from 556,874 tonnes during the same period last year. It has '
'commitments to export another 658,999 tonnes this year. REUTER '),
(['soybean', 'red-bean', 'oilseed', 'japan'],
'The Tokyo Grain Exchange said it will raise the margin requirement on '
'the spot and nearby month for U.S. And Chinese soybeans and red beans, '
'effective March 2. Spot April U.S. Soybean contracts will increase to '
'90,000 yen per 15 tonne lot from 70,000 now. Other months will stay '
'unchanged at 70,000, except the new distant February requirement, which '
'will be set at 70,000 from March 2. Chinese spot March will be set at '
'110,000 yen per 15 tonne lot from 90,000. The exchange said it raised '
'spot March requirement to 130,000 yen on contracts outstanding at March '
'13. Chinese nearby April rises to 90,000 yen from 70,000. Other months '
'will remain unchanged at 70,000 yen except new distant August, which '
'will be set at 70,000 from March 2. The new margin for red bean spot '
'March rises to 150,000 yen per 2.4 tonne lot from 120,000 and to 190,000 '
'for outstanding contracts as of March 13. The nearby April requirement '
'for red beans will rise to 100,000 yen from 60,000, effective March 2. '
'The margin money for other red bean months will remain unchanged at '
'60,000 yen, except new distant August, for which the requirement will '
'also be set at 60,000 from March 2. REUTER '),
..
..
Gestione delle etichette
In particolare, si tenga presente che invece di avere una singola etichetta di argomento associata a un documento, abbiamo più argomenti. Per aumentare l’efficacia del classificatore per il natural language processing, è necessario assegnare una sola etichetta di classe a ciascun documento. Tuttavia, noterai anche che alcune delle etichette sono in realtà tag di posizione geografica, come “giappone” o “thailandia”. Poiché ci occupiamo esclusivamente di argomenti e non di paesi, desideriamo rimuoverli prima di selezionare il nostro argomento.
Lo specifico metodo che useremo per eseguire questa operazione è piuttosto semplice. Elimineremo i nomi dei paesi e quindi selezioneremo il primo argomento rimanente nell’elenco. Se non ci sono argomenti associati, elimineremo l’articolo dal nostro corpus. Nell’output sopra, questo si ridurrà a una struttura di dati che assomiglia a:
..
..
('grain',
'Thailand exported 84,960 tonnes of rice in the week ended February 24, '
'up from 80,498 the previous week, the Commerce Ministry said. It said '
'government and private exporters shipped 27,510 and 57,450 tonnes '
'respectively. Private exporters concluded advance weekly sales for '
'79,448 tonnes against 79,014 the previous week. Thailand exported '
'689,038 tonnes of rice between the beginning of January and February 24, '
'up from 556,874 tonnes during the same period last year. It has '
'commitments to export another 658,999 tonnes this year. REUTER '),
('soybean',
'The Tokyo Grain Exchange said it will raise the margin requirement on '
'the spot and nearby month for U.S. And Chinese soybeans and red beans, '
'effective March 2. Spot April U.S. Soybean contracts will increase to '
'90,000 yen per 15 tonne lot from 70,000 now. Other months will stay '
'unchanged at 70,000, except the new distant February requirement, which '
'will be set at 70,000 from March 2. Chinese spot March will be set at '
'110,000 yen per 15 tonne lot from 90,000. The exchange said it raised '
'spot March requirement to 130,000 yen on contracts outstanding at March '
'13. Chinese nearby April rises to 90,000 yen from 70,000. Other months '
'will remain unchanged at 70,000 yen except new distant August, which '
'will be set at 70,000 from March 2. The new margin for red bean spot '
'March rises to 150,000 yen per 2.4 tonne lot from 120,000 and to 190,000 '
'for outstanding contracts as of March 13. The nearby April requirement '
'for red beans will rise to 100,000 yen from 60,000, effective March 2. '
'The margin money for other red bean months will remain unchanged at '
'60,000 yen, except new distant August, for which the requirement will '
'also be set at 60,000 from March 2. REUTER '),
..
..
..
..
def obtain_topic_tags():
"""
Apre il file dell'elenco degli argomenti e importa tutti i nomi
degli argomenti facendo attenzione a rimuovere il finale "\ n" da ogni parola.
"""
topics = open(
"data/all-topics-strings.lc.txt", "r"
).readlines()
topics = [t.strip() for t in topics]
return topics
def filter_doc_list_through_topics(topics, docs):
"""
Legge tutti i documenti e crea un nuovo elenco di due tuple che
contengono una singola voce di funzionalità e il corpo del testo,
invece di un elenco di argomenti. Rimuove tutte le caratteristiche
geografiche e conserva solo quei documenti che hanno almeno un
argomento non geografico.
"""
ref_docs = []
for d in docs:
if d[0] == [] or d[0] == "":
continue
for t in d[0]:
if t in topics:
d_tup = (t, d[1])
ref_docs.append(d_tup)
break
return ref_docs
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
filename = "data/reut2-000.sgm"
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
doc = parser.parse(open(filename, 'rb'))
# Ottenere i tags e filtrare il documento con essi
topics = obtain_topic_tags()
ref_docs = filter_doc_list_through_topics(topics, docs)
pprint.pprint(list(doc))
L’output è il seguente:
..
..
('acq',
'Security Pacific Corp said it completed its planned merger with Diablo '
'Bank following the approval of the comptroller of the currency. Security '
'Pacific announced its intention to merge with Diablo Bank, headquartered '
'in Danville, Calif., in September 1986 as part of its plan to expand its '
'retail network in Northern California. Diablo has a bank offices in '
'Danville, San Ramon and Alamo, Calif., Security Pacific also said. '
'Reuter '),
('earn',
'Shr six cts vs five cts Net 188,000 vs 130,000 Revs 12.2 mln vs 10.1 mln '
'Avg shrs 3,029,930 vs 2,764,544 12 mths Shr 81 cts vs 1.45 dlrs Net '
'2,463,000 vs 3,718,000 Revs 52.4 mln vs 47.5 mln Avg shrs 3,029,930 vs '
'2,566,680 NOTE: net for 1985 includes 500,000, or 20 cts per share, for '
'proceeds of a life insurance policy. includes tax benefit for prior qtr '
'of approximately 150,000 of which 140,000 relates to a lower effective '
'tax rate based on operating results for the year as a whole. Reuter '),
..
..
Ora possiamo pre-elaborare i dati per inserirli nel classificatore.
Vettorizzazione
In questa fase disponiamo di una vasta raccolta di coppie di tuple, ognuna contenente un’etichetta di classe e un corpo di testo grezzo proveniente dalle lezioni. La domanda ovvia che ci poniamo è come trasformare il corpo del testo grezzo in una rappresentazione numerica utilizzabile da un classificatore.
Affrontiamo questo problema con un processo chiamato vettorizzazione. La vettorizzazione converte testi grezzi di lunghezza variabile in un formato numerico che il classificatore può elaborare.
Raggiungiamo questo obiettivo creando alcuni token a partire da una stringa. Un token rappresenta una singola parola (o un gruppo di parole) estratta da un documento, utilizzando spazi bianchi o punteggiatura come delimitatori. Questo processo include anche numeri presenti nella stringa, trattandoli come parole. Dopo aver generato l’elenco di token, assegniamo a ciascuno un identificatore intero, così da poterli elencare.
Dopo aver generato l’elenco dei token, contiamo il numero di occorrenze di ciascun token in un documento. Infine, normalizziamo questi token per ridurre l’importanza di quelli che compaiono frequentemente (come “a”, “the”). Questo approccio prende il nome di Bag Of Words.
Bag of Words
La rappresentazione Bag Of Words assegna un vettore a ogni documento, in cui ogni componente ha un valore reale che indica l’importanza dei token (cioè delle “parole”) presenti in quel documento.
Dopo aver analizzato l’intero corpus di documenti (valutando tutti i token possibili), conosciamo il numero totale di token distinti e quindi anche la lunghezza del vettore token, che risulta fissa e identica per qualsiasi documento, indipendentemente dalla lunghezza.
Questo consente al classificatore di disporre di una serie di features basate sulla frequenza dei token. Inoltre, il vettore dei token di un documento funge da campione per l’addestramento del classificatore.
In sostanza, rappresentiamo l’intero corpus come una grande matrice: ogni riga corrisponde a un documento, mentre ogni colonna rappresenta la frequenza di un token in quel documento. Questo costituisce il processo di vettorizzazione.
Notiamo che la vettorizzazione ignora il posizionamento relativo delle parole nel documento, considerando solo la frequenza. Tuttavia, tecniche di apprendimento automatico più evolute sfruttano anche queste informazioni per migliorare la classificazione.
Term-Frequency Inverse Document-Frequency
Uno dei principali limiti della rappresentazione Bag Of Words è il “rumore” causato da parole molto comuni, come “un”, “il”, “lui”, “lei”, ecc. Queste parole offrono poco contesto utile, ma la loro alta frequenza può oscurare parole realmente significative.
Per affrontare questo problema applichiamo una trasformazione chiamata Term-Frequency Inverse Document-Frequency (TF-IDF). Il valore TF-IDF di un token cresce in proporzione alla sua frequenza nel documento, ma viene normalizzato in base alla frequenza nel corpus. Questo riduce l’importanza di parole comuni su scala globale, privilegiando quelle rilevanti per singoli documenti.
Questo è esattamente ciò che ci serve, poiché parole come “un” o “il” compaiono in tutto il corpus, mentre termini come “gatto” possono essere frequenti solo in documenti specifici. Così attribuiamo a “gatto” un peso relativo superiore rispetto a “un” o “lui” all’interno del documento.
Non entriamo nel dettaglio del calcolo del TF-IDF, ma se vogliamo approfondire possiamo leggere l’articolo di Wikipedia sull’argomento.
Vogliamo quindi combinare il processo di vettorizzazione con il TF-IDF per ottenere una matrice normalizzata di occorrenze documento-token. Utilizzeremo questa matrice per fornire al classificatore un elenco di “features” su cui allenarsi.
Implementazione
Fortunatamente, gli sviluppatori di scikit-learn hanno capito che vettorializzare e trasformare testi in questo modo è un’operazione molto utile e frequente, perciò hanno incluso nella libreria la classe TfidfVectorizer.
Possiamo utilizzare questa classe per trasformare il nostro elenco di coppie di tuple, che rappresentano le etichette di classe e il testo grezzo, in un vettore di etichette di classe e in una matrice sparsa. Questi elementi rappresentano rispettivamente la vettorizzazione dei testi non elaborati e l’applicazione del TF-IDF.
Poiché i classificatori di scikit-learn richiedono due strutture di dati distinte per l’addestramento, ovvero \(y\), il vettore delle etichette di classe (le “risposte”) associate a un insieme ordinato di documenti, e \(X\), la matrice sparsa TF-IDF del testo, modifichiamo la nostra lista di tuple per ottenere \(y\) e \(X\). Ecco il codice per crearli:
..
from sklearn.feature_extraction.text import TfidfVectorizer
..
..
def create_tfidf_training_data(docs):
"""
Crea un elenco di corpus di documenti (rimuovendo le etichette della classe),
quindi applica la trasformazione TF-IDF a questo elenco.
La funzione restituisce sia il vettore etichetta di classe (y) che
la matrice token / feature corpus (X).
"""
# Crea le classi di etichette per i dati di addestramento
y = [d[0] for d in docs]
# Crea la lista dei corpus del documenti
corpus = [d[1] for d in docs]
# Create la vettorizzazione TF-IDF e trasforma il corpus
vectorizer = TfidfVectorizer(min_df=1)
X = vectorizer.fit_transform(corpus)
return X, y
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
filename = "data/reut2-000.sgm"
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
docs = list(parser.parse(open(filename, 'rb')))
# Ottenere i tags e filtrare il documento con essi
topics = obtain_topic_tags()
ref_docs = filter_doc_list_through_topics(topics, docs)
# Vettorizzazione e TF-IDF
X, y = create_tfidf_training_data(ref_docs)
A questo punto abbiamo due componenti per i nostri dati di addestramento. Il primo,[label]X[/label], è una matrice di occorrenze di token di documento. Il secondo, [label]y[/label], è un vettore (che corrisponde all’ordine della matrice) che contiene le corrette etichette di classe per ciascuno dei documenti. Questo è tutto ciò di cui abbiamo bisogno per iniziare l’addestramento e il test della Support Vector Machine.
Addestrare un Support Vector Machine
Per addestrare la Support Vector Machine per il natural language processing è necessario fornirle sia un insieme di features (la matrice [label]X[/label]) sia un insieme di etichette di addestramento “supervisionato”, in questo caso le classi [label]$[/label]. Tuttavia, abbiamo anche bisogno di un mezzo per valutare le prestazioni del classificatore dopo la sua fase di addestramento.
Un approccio consiste nel provare semplicemente a classificare alcuni dei documenti che formano il corpus utilizzato per addestrarlo. Tale procedura di valutazione è nota come test in-sample. Tuttavia, questo non è un meccanismo particolarmente efficace per valutare le prestazioni del sistema.
In poche parole, il classificatore ha già “visto” questi dati e gli è stato detto come agire su di essi, quindi è molto probabile che classifichi correttamente il documento. Questo quasi certamente sovrastimerà le reali prestazioni di test out-of-sample. Quindi dobbiamo fornire al classificatore i dati che non ha utilizzato per l’addestramento, come mezzo di test più realistico.
Tuttavia, non è chiaro da dove ottenere questi nuovi dati. Un approccio potrebbe essere quello di creare un nuovo corpus con alcuni nuovi dati. Tuttavia, in realtà è probabile che ciò sia costoso in termini di tempo e / o processi aziendali. Un approccio alternativo consiste nel suddividere l’insieme di addestramento in due sottoinsiemi distinti, uno dei quali viene utilizzato per l’addestramento e l’altro per i test. Questo è noto come training-test split.
Divisione in Training-Test
Tale partizione ci consente di addestrare il classificatore esclusivamente sulla prima partizione e quindi di classificare le sue prestazioni con la seconda partizione. Questo permette di avere una visione migliore circa le possibili prestazioni future con dati reali “out-of-sample”.
A questo punto ci si può domandare quale percentuale dei dati utilizzare per l’addestramento e quale per i test. Chiaramente quanto più viene utilizzato per l’addestramento, tanto “migliore” sarà il classificatore perché avrà visto più dati. Tuttavia, più dati di addestramento significano meno dati di test e di conseguenza una stima più scarsa della sua reale capacità di classificazione. In pratica, è comune prevedere circa il 70-80% dei dati per l’addestramento e utilizzare il resto per i test.
Implementazione
Dato che il training-test split è un’operazione così comune nell’apprendimento automatico, gli sviluppatori di scikit-learn hanno fornito il metodo train_test_split per creare automaticamente la divisione da un dataset di input. Ecco il codice che fornisce la suddivisione:
from sklearn.model_selection import train_test_split
..
..
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
L’argomento della parola chiave test_size controlla la dimensione del set di test, in questo caso il 20%. L’argomento della parola chiave random_state controlla il fonte casuale per la selezione casuale della partizione.
Il passaggio successivo consiste nel creare effettivamente la Support Vector Machine per il natural language processing e addestrarla. In questo caso useremo la classe SVC (Support Vector Classifier) di scikit-learn. Gli diamo i parametri [label]C = 1000000.0[/label], [label]\gamma = 0.0[/label] e scegliamo un kernel radiale. Per capire da dove provengono questi parametri, consultare l’articolo su Support Vector Machines.
Il codice seguente importa la classe SVC e quindi la adatta ai dati di addestramento:
from sklearn.svm import SVC
..
..
def train_svm(X, y):
"""
Crea e addestra la Support Vector Machine.
"""
svm = SVC(C=1000000.0, gamma=0.0, kernel='rbf')
svm.fit(X, y)
return svm
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
filename = "data/reut2-000.sgm"
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
docs = list(parser.parse(open(filename, 'rb')))
# Ottenere i tags e filtrare il documento con essi
topics = obtain_topic_tags()
ref_docs = filter_doc_list_through_topics(topics, docs)
# Vettorizzazione e TF-IDF
X, y = create_tfidf_training_data(ref_docs)
# Crea il training-test split dei dati
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Crea ed addestra la Support Vector Machine
svm = train_svm(X_train, y_train)
Ora che l’SVM è stata addestrata, dobbiamo valutarne le prestazioni sui dati di test.
Prestazioni del Natural Language Processing
Le due principali metriche delle prestazioni che prenderemo in considerazione per questo classificatore supervisionato sono il tasso di successo(hit-rate) e la confusion-matrix. Il primo è semplicemente il rapporto tra le associazioni corrette e le associazioni totali ed è solitamente espresso in percentuale.
La matrice di confusione entra più in dettaglio e fornisce statistiche sui veri positivi, veri negativi, falsi positivi e falsi negativi. In un sistema di classificazione binario, con un’etichettatura di classe “vero” o “falso”, questi caratterizzano la velocità con cui il classificatore classifica correttamente qualcosa come vero o falso quando è, rispettivamente, vero o falso, e classifica anche erroneamente qualcosa come vero o falso quando è, rispettivamente, falso o vero.
Una matrice di confusione non deve essere limitata a una situazione di classificatore binario. Per più gruppi di classi (come nel nostro esempio con il dataset di Reuters) avremo una matrice \(N\times N\), dove \(N\) è il numero di etichette di classe (o argomenti del documento).
Scikit-learn ha funzioni sia per il calcolo del hit-rate sia per la matrice di confusione di un classificatore supervisionato. Il primo è un metodo dello stesso classificatore chiamato score. Quest’ultimo deve essere importato dalla libreria metrics.
La prima attività è creare un array di previsioni dal set di test X_test. Questo conterrà semplicemente le etichette di classe previste dall’SVM tramite il set di dati previsto per il test (20%). Questo array di previsione viene utilizzata per creare la matrice di confusione. Da notare che la funzione confusion_matrix accetta sia l’array di previsione pred sia le etichette della classe corretta y_test per produrre la matrice. Inoltre, si crea l’hit-rate tramite lo score di entrambi i sottoinsiemi X_test e y_test del set di dati:
..
..
from sklearn.metrics import confusion_matrix
..
..
if __name__ == "__main__":
..
..
# Crea ed addestra la Support Vector Machine
svm = train_svm(X_train, y_train)
# Crea un array delle predizioni con i dati di test
pred = svm.predict(X_test)
# Calcolo del hit-rate e della confusion matrix per ogni modello
print(svm.score(X_test, y_test))
print(confusion_matrix(pred, y_test))
0.660194174757
[[21 0 0 0 2 3 0 0 0 1 0 0 0 0 1 1 1 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 1 0 0 1 26 0 0 0 1 0 1 0 1 0 0 0 0 0]
[ 0 0 0 0 0 0 2 0 0 0 0 0 0 0 0 0 0 0 1]
[ 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 1 0 0 0 0 3 0 0 0 0 0 0 0 0 0]
[ 3 0 0 1 2 2 3 0 1 1 6 0 1 0 0 0 2 3 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
Quindi abbiamo un tasso di successo della classificazione del 66%, con una matrice di confusione che ha voci principalmente sulla diagonale (cioè la corretta assegnazione dell’etichetta di classe). Si noti che poiché stiamo utilizzando solo un singolo file dal set Reuters (numero 000), non vedremo l’intero set di etichette di classe e quindi la nostra matrice di confusione è di dimensioni inferiori rispetto a quella in cui avessimo usato l’intero set di dati.
Set completo di dati
Per utilizzare il set di dati completo, possiamo modificare la funzione __main__ per caricare tutti i 21 file Reuters e addestrare SVM sul set di dati completo. Possiamo quindi calcolare la completa performance dell’hit-rate. Ho trascurato di includere l’output della matrice di confusione poiché è di grandi dimensioni a causa del numero totale di etichette di classe all’interno di tutti i documenti. Da notare che ci vorrà del tempo! Sul mio sistema sono necessari ci vogliono circa 30-45 per completare l’esecuzione.
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
files = ["data/reut2-%03d.sgm" % r for r in range(0, 22)]
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
docs = []
for fn in files:
for d in parser.parse(open(fn, 'rb')):
docs.append(d)
..
..
print(svm.score(X_test, y_test))
Per tutti i corpus, l’hit-rate del sistema è:
0.835971855761
Ci sono molti modi per migliorare questo valore. In particolare, possiamo eseguire una Grid Search Cross-Validation, che è un metodo per determinare i parametri ottimali per il classificatore in modo da raggiungere il miglior tasso di successo (o altra metrica di scelta).
Negli articoli successivi discuteremo tali procedure di ottimizzazione e spiegheremo come un classificatore come questo può essere aggiunto a un sistema di produzione in un contesto di data-science o di finanza quantitativa.
Codice completo dell’implementazione in Python
Di seguito il codice completo per l’applicazione del natural language processing scritta in Python 3.7.x:
import html
import pprint
import re
from html.parser import HTMLParser
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix
class ReutersParser(HTMLParser):
"""
ReutersParser è una sottoclasse HTMLParser e viene utilizzato per aprire file SGML
associati al dataset di Reuters-21578.
Il parser è un generatore e produrrà un singolo documento alla volta.
Poiché i dati verranno suddivisi in blocchi durante l'analisi, è necessario
mantenere alcuni stati interni di quando i tag sono stati "inseriti" e
"eliminati".
Da qui le variabili booleani in_body, in_topics e in_topic_d.
"""
def __init__(self, encoding='latin-1'):
"""
Inizializzo la superclasse (HTMLParser) e imposto il parser.
Imposto la decodifica dei file SGML con latin-1 come default.
"""
html.parser.HTMLParser.__init__(self)
self._reset()
self.encoding = encoding
def _reset(self):
"""
Viene chiamata solo durante l'inizializzazione della classe parser
e quando è stata generata una nuova tupla topic-body. Si
resetta tutto lo stato in modo che una nuova tupla possa essere
successivamente generato.
"""
self.in_body = False
self.in_topics = False
self.in_topic_d = False
self.body = ""
self.topics = []
self.topic_d = ""
def parse(self, fd):
"""
parse accetta un descrittore di file e carica i dati in blocchi
per ridurre al minimo l'utilizzo della memoria.
Quindi produce nuovi documenti man mano che vengono analizzati.
"""
self.docs = []
for chunk in fd:
self.feed(chunk.decode(self.encoding))
for doc in self.docs:
yield doc
self.docs = []
self.close()
def handle_starttag(self, tag, attrs):
"""
Questo metodo viene utilizzato per determinare cosa fare quando
il parser incontra un particolare tag di tipo "tag".
In questo caso, impostiamo semplicemente i valori booleani
interni su True se è stato trovato quel particolare tag.
"""
if tag == "reuters":
pass
elif tag == "body":
self.in_body = True
elif tag == "topics":
self.in_topics = True
elif tag == "d":
self.in_topic_d = True
def handle_endtag(self, tag):
"""
Questo metodo viene utilizzato per determinare cosa fare
quando il parser termina con un particolare tag di tipo "tag".
"""
if tag == "reuters":
self.body = re.sub(r'\s+', r' ', self.body)
self.docs.append((self.topics, self.body))
self._reset()
elif tag == "body":
self.in_body = False
elif tag == "topics":
self.in_topics = False
elif tag == "d":
self.in_topic_d = False
self.topics.append(self.topic_d)
self.topic_d = ""
def handle_data(self, data):
"""
I dati vengono semplicemente aggiunti allo stato appropriato
per quel particolare tag, fino a quando non viene visualizzato
il tag di chiusura finale.
"""
if self.in_body:
self.body += data
elif self.in_topic_d:
self.topic_d += data
def obtain_topic_tags():
"""
Apre il file dell'elenco degli argomenti e importa tutti i nomi
degli argomenti facendo attenzione a rimuovere il finale "\ n" da ogni parola.
"""
topics = open(
"data/all-topics-strings.lc.txt", "r"
).readlines()
topics = [t.strip() for t in topics]
return topics
def filter_doc_list_through_topics(topics, docs):
"""
Legge tutti i documenti e crea un nuovo elenco di due tuple che
contengono una singola voce di funzionalità e il corpo del testo,
invece di un elenco di argomenti. Rimuove tutte le caratteristiche
geografiche e conserva solo quei documenti che hanno almeno un
argomento non geografico.
"""
ref_docs = []
for d in docs:
if d[0] == [] or d[0] == "":
continue
for t in d[0]:
if t in topics:
d_tup = (t, d[1])
ref_docs.append(d_tup)
break
return ref_docs
def create_tfidf_training_data(docs):
"""
Crea un elenco di corpus di documenti (rimuovendo le etichette della classe),
quindi applica la trasformazione TF-IDF a questo elenco.
La funzione restituisce sia il vettore etichetta di classe (y) che
la matrice token / feature corpus (X).
"""
# Crea le classi di etichette per i dati di addestramento
y = [d[0] for d in docs]
# Crea la lista dei corpus del documenti
corpus = [d[1] for d in docs]
# Create la vettorizzazione TF-IDF e trasforma il corpus
vectorizer = TfidfVectorizer(min_df=1)
X = vectorizer.fit_transform(corpus)
return X, y
def train_svm(X, y):
"""
Crea e addestra la Support Vector Machine.
"""
svm = SVC(C=1000000.0, gamma=0.0, kernel='rbf')
svm.fit(X, y)
return svm
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
filename = "data/reut2-000.sgm"
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
docs = list(parser.parse(open(filename, 'rb')))
if __name__ == "__main__":
# Apre il primo set di dati Reuters e crea il parser
files = ["data/reut2-%03d.sgm" % r for r in range(0, 22)]
parser = ReutersParser()
# Analizza il documento e forza tutti i documenti generati
# in un elenco in modo che possano essere stampati sulla console
docs = []
for fn in files:
for d in parser.parse(open(fn, 'rb')):
docs.append(d)
# Ottenere i tags e filtrare il documento con essi
topics = obtain_topic_tags()
ref_docs = filter_doc_list_through_topics(topics, docs)
# Vettorizzazione e TF-IDF
X, y = create_tfidf_training_data(ref_docs)
# Crea il training-test split dei dati
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Crea ed addestra la Support Vector Machine
svm = train_svm(X_train, y_train)
# Crea un array delle predizioni con i dati di test
pred = svm.predict(X_test)
# Calcolo del hit-rate e della confusion matrix per ogni modello
print(svm.score(X_test, y_test))
print(confusion_matrix(pred, y_test))
Il codice completo presentato in questa lezione è disponibile nel seguente repository GitHub: “https://github.com/tradingquant-it/TQResearch“