

In questa lezione del corso per il trading automatico sul forex descriviamo effettuare il backtest e visualizzare le performance di una strategia multiday sul mercato Forex.
A tale scopo dobbiamo introdurre alcune nuove funzionalità al sistema di trading automatico sul forex che stiamo costruendo in questo corso:
- Generazione di dati tick simulati: poiché scaricare molti dati tick sul Forex risulta complesso (almeno per alcuni dei provider che utilizziamo!), abbiamo preferito generare dati tick casuali per testare il sistema.
- Backtest multiday: per rendere il sistema TQforex più utile, abbiamo aggiunto la funzionalità di backtest su più giorni di dati tick e su più coppie di valute.
- Tracciamento dei risultati del backtesting: oltre all’output della console, ora visualizziamo una curva di equity e il drawdown storico utilizzando la libreria Seaborn per creare i grafici delle performance.
Script per Simulare i Dati di Tick
Una funzionalità estremamente importante per un sistema di trading consiste nel poter eseguire un backtest su dati tick storici che coprano più giorni. In passato il sistema gestiva il backtest solo tramite un singolo file. Questa soluzione non risultava scalabile, dato che caricava tutto il file in memoria per convertirlo in un DataFrame di pandas. Sebbene i file dei dati tick non siano enormi (circa 3,5 MB ciascuno), gestire più coppie di valute su mesi o anni genera rapidamente grandi quantità di dati.
Per costruire una funzionalità che supporti più giorni e file, abbiamo iniziato a scaricare dati dal feed tick storico di DukasCopy. Tuttavia, abbiamo incontrato problemi durante il download dei file necessari per i test.
Dato che non riteniamo essenziale disporre di serie storiche reali per testare il sistema, abbiamo preferito scrivere uno script che generasse automaticamente dati di tick simulati. Abbiamo inserito questo script nel file scripts/generate_simulated_pair.py, che puoi trovare qui.
Lo script crea un elenco di timestamp distribuiti casualmente, associando a ciascuno valori bid/ask e volumi. Manteniamo costante lo spread tra bid e ask, mentre i prezzi bid e ask seguono un random walk.
Poiché non intendiamo testare strategie reali con questi dati, non ci preoccupiamo delle loro proprietà statistiche o dei valori assoluti rispetto ai dati reali del Forex. Ci interessa garantire il formato corretto e una lunghezza approssimativa per testare efficacemente il sistema di backtesting su più giorni.
Creazione dei file
Attualmente lo script genera dati Forex per tutto il mese di gennaio 2017. Utilizziamo la libreria Calendar di Python per considerare i giorni lavorativi (anche se non abbiamo ancora escluso le festività). A tale scopo creiamo file nel formato BBBQQQ_YYYYMMDD.csv, dove BBBQQQ indica la coppia di valute (es. EURUSD) e YYYYMMDD rappresenta la data (es. 20170112).
Inseriamo questi file nella directory CSV_DATA_DIR, definita nel file settings.py dell’applicazione.
Per generare i dati, basta eseguire il seguente comando, sostituendo BBBQQQ con la coppia di valute desiderata, ad esempio EURUSD:
python scripts/generate_simulated_pair.py BBBQQQ
Il file richiede una modifica per generare dati su più mesi o anni. Ogni file di tick giornalieri occupa circa 3,2 MB di spazio.
In futuro modificheremo questo script per generare dati su un periodo più ampio. Ci baseremo su uno specifico elenco di coppie di valute invece di utilizzare valori codificati. Per ora, però, questa versione ci basta per iniziare.
Ricordiamo che il formato corrisponde esattamente a quello dei dati storici dei tick forniti da DukasCopy. Il set di dati che stiamo attualmente utilizzando.
Implementazione di un Backtest Multiday
Dopo aver generato i dati tick simulati, per calcolare le performance di una strategia multiday passiamo all’implementazione del backtesting su più giorni. Per il momento preferiamo lavorare con un set di file CSV, uno per ogni giorno e per ogni coppia di valute. In futuro prevediamo di utilizzare un sistema di archiviazione dati più robusto, come PyTables con HDF5,
Questa soluzione scala bene con l’aumento del numero di giorni. La natura event-driven del nostro sistema ci permette di mantenere in memoria solo N file contemporaneamente, dove N rappresenta il numero di coppie di valute scambiate in un dato giorno.
Alla base del sistema abbiamo pensato che la classe HistoricCSVPriceHandler continuerà a usare il metodo stream_next_tick. Dobbiamo però prevedere una modifica: dovrà gestire i dati di più giorni caricandoli in modo sequenziale.
Termineremo il backtest quando riceveremo l’eccezione StopIteration generata dal metodo next(..) su self.all_pairs, come mostrato in questo frammento di pseudocodice:
# price.py
..
..
def stream_next_tick(self):
..
..
try:
index, row = next(self.all_pairs)
except StopIteration:
return
else:
..
..
# Aggiungere un tick alla coda
Nella nuova implementazione, questo snippet viene modificato come segue:
# price.py
..
..
def stream_next_tick(self):
..
..
try:
index, row = next(self.cur_date_pairs)
except StopIteration:
# Fine dei dati per l'attuale giorno
if self._update_csv_for_day():
index, row = next(self.cur_date_pairs)
else: # Fine dei dati
self.continue_backtest = False
return
..
..
# Aggiunta del tick nella coda
In questo frammento, quando si genera un StopIteration, verifichiamo il risultato di self._update_csv_for_day(). Se il risultato è True, continuiamo il backtest (dato che il self.cur_date_pairs potrebbe essere cambiato nei dati dei giorni successivi). Se invece il risultato è False, interrompiamo il backtest.
Questo approccio risulta molto efficiente in termini di memoria, perché carichiamo solo un numero limitato di giorni di dati alla volta. Così possiamo eseguire mesi di backtesting e siamo limitati soltanto dalla velocità di elaborazione della CPU e dalla quantità di dati che riusciamo a generare o acquisire.
Aggiorniamo quindi la documentazione per indicare che ora il sistema si aspetta più giorni di dati in un formato specifico, collocati in una directory particolare che dobbiamo specificare.
Performance di una strategia multiday
Un backtest serve a poco se non riusciamo a visualizzare le performance di una strategia multiday nel tempo. Anche se il sistema si è basato finora sulla console, in questa lezione iniziamo a introdurre le basi per un’interfaccia utente grafica (GUI).
In particolare, creiamo i classici “tre pannelli” di grafici che spesso accompagnano le metriche di performance dei sistemi di trading quantitativo: la curva equity, il profilo dei rendimenti e la curva dei drawdown. Calcoliamo tutti e tre per ogni tick e li salviamo in un file chiamato equity.csv nella directory specificata in OUTPUT_RESULTS_DIR di settings.py.
Per visualizzare i dati utilizziamo una libreria chiamata Seaborn, che genera grafici di alta qualità con un aspetto nettamente migliore rispetto ai grafici predefiniti di Matplotlib. La grafica somiglia molto a quella prodotta dal pacchetto ggplot2 di R. Inoltre, Seaborn si basa su Matplotlib, quindi possiamo ancora utilizzare l’API di Matplotlib.
Per permettere la visualizzazione delle performance di una strategia multiday, abbiamo creato lo script output.py che si trova nella directory backtest/. Il codice di questo script è il seguente:
# output.py
import os, os.path
import pandas as pd
import matplotlib
try:
matplotlib.use('TkAgg')
except:
pass
import matplotlib.pyplot as plt
import seaborn as sns
from qsforex.settings import OUTPUT_RESULTS_DIR
if __name__ == "__main__":
"""
A simple script to plot the balance of the portfolio, or
"equity curve", as a function of time.
It requires OUTPUT_RESULTS_DIR to be set in the project
settings.
"""
sns.set_palette("deep", desat=.6)
sns.set_context(rc={"figure.figsize": (8, 4)})
equity_file = os.path.join(OUTPUT_RESULTS_DIR, "equity.csv")
equity = pd.io.parsers.read_csv(
equity_file, parse_dates=True, header=0, index_col=0
)
# Plot three charts: Equity curve, period returns, drawdowns
fig = plt.figure()
fig.patch.set_facecolor('white') # Set the outer colour to white
# Plot the equity curve
ax1 = fig.add_subplot(311, ylabel='Portfolio value')
equity["Equity"].plot(ax=ax1, color=sns.color_palette()[0])
# Plot the returns
ax2 = fig.add_subplot(312, ylabel='Period returns')
equity['Returns'].plot(ax=ax2, color=sns.color_palette()[1])
# Plot the returns
ax3 = fig.add_subplot(313, ylabel='Drawdowns')
equity['Drawdown'].plot(ax=ax3, color=sns.color_palette()[2])
# Plot the figure
plt.show()
Come possiamo vedere, importiamo Seaborn nello script, apriamo il file equity.csv in un DataFrame pandas e creiamo tre grafici: la curva di equity, i rendimenti e il drawdown.
Il grafico del drawdown viene calcolato da una funzione di supporto che si trova in performance/performance.py e che richiamiamo dalla classe Portfolio alla fine di ogni backtest.
Risultati
Ecco un esempio di performance di una strategia multiday MovingAverageCrossStrategy, utilizzando un set di dati EURUSD generato casualmente per il mese di gennaio 2017:
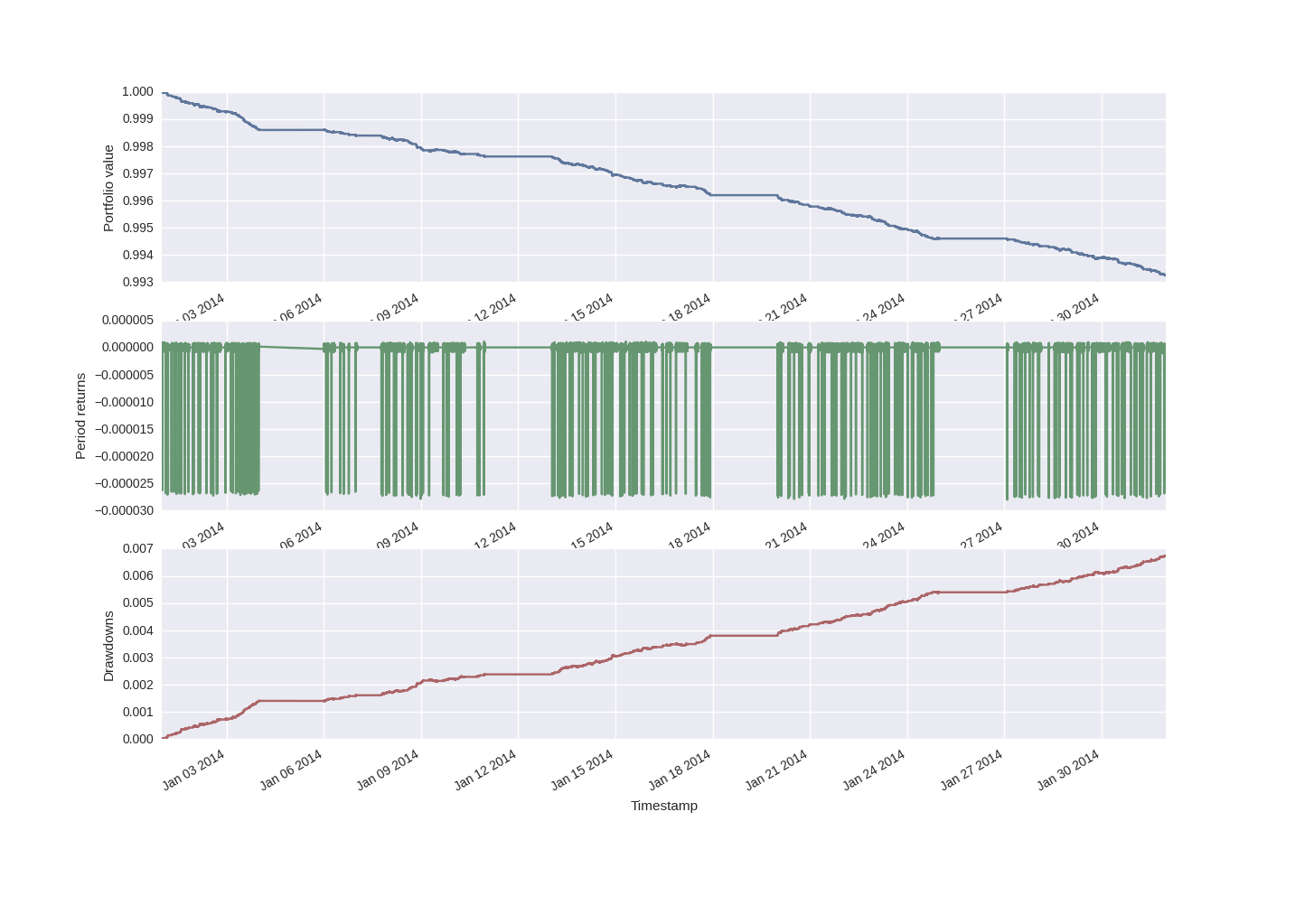
In particolare, possiamo notare le sezioni piatte della curva azionaria durante i fine settimana, quando non abbiamo dati disponibili (almeno per questo set di dati simulato). Inoltre, osserviamo che la strategia perde denaro in modo piuttosto prevedibile su questo set di dati simulato in modo casuale.
Questo rappresenta un buon test per il nostro sistema. Stiamo semplicemente tentando di seguire una tendenza su una serie temporale casuale. Le perdite derivano dallo spread fisso introdotto durante la simulazione.
Questo ci rende evidente che, per ottenere profitti consistenti nel trading algoritmico del Forex ad alta frequenza, dobbiamo possedere uno specifico vantaggio quantificabile che generi rendimenti positivi superiori ai costi di transazione come spread e slippage.
Tratteremo in modo più approfondito questo tema fondamentale nelle prossime lezioni di questo corso dedicato al trading algoritmico del Forex.
Conclusioni
Calcoli della posizione di fissaggio
Abbiamo notato che i calcoli della classe Position non riflettono esattamente il metodo con cui OANDA (il broker che utilizziamo nel sistema trading.py) calcola i trade sui cross valutari.
Per questo motivo, uno dei prossimi passi fondamentali sarà eseguire e testare le modifiche al file position.py e aggiornare anche gli unit test presenti in position_test.py. Queste modifiche avranno un effetto a catena sui file portfolio.py e portfolio_test.py.
Valutazione della prestazione
Ora disponiamo di un set base di grafici delle performance di una strategia multiday, che comprende la curva di equity, il profilo dei rendimenti e la serie dei drawdown, ma dobbiamo integrare misure di performance più avanzate.
In particolare, vogliamo calcolare metriche a livello di strategia, come lo Sharpe Ratio, l’Information Ratio e il Sortino Ratio. Inoltre, ci servono statistiche sui drawdown, inclusa la distribuzione dei drawdown e il massimo drawdown. Altri indicatori utili saranno il tasso di crescita annuale composto (CAGR) e il rendimento totale.
A livello di trade o posizione, desideriamo analizzare metriche come profitto/perdita medio, massimo profitto/perdita, rapporto di profitto e rapporto di vincita/perdita. Poiché abbiamo costruito la classe Position come parte centrale del software, potremo generare facilmente queste metriche aggiungendo alcuni metodi dedicati.
Il codice completo presentato in questa lezione, basato sul sistema di trading automatico sul Forex TQforex, è disponibile nel seguente repository GitHub: https://github.com/tradingquant-it/TQforex.”