Fino ad ora, tutte le strategie di trading che abbiamo esplorato con DataTrader si basano su dati giornalieri OHLCV delle azioni. In questo articolo, passiamo a una strategia intraday di machine learning, effettuando un backtest completo. Implementiamo un algoritmo predittivo basato sul machine learning supervisionato, con l’obiettivo di prevedere le variazioni direzionali dei rendimenti azionari su base minuto per minuto.
Introduzione
Iniziamo definendo gli obiettivi predittivi per i dati di prezzo degli asset e discutiamo il problema dello sbilanciamento delle classi, una situazione comune nella previsione quantitativa dei rendimenti.
Successivamente, costruiamo un modello predittivo utilizzando la libreria Scikit-Learn di Python, sperimentando diversi classificatori di machine learning. Presentiamo anche alcune funzioni utili per adattare questi modelli a un ambiente intraday di tipo “online”.
Mostriamo infine l’implementazione di una classe Strategy e di uno script di backtest che permettono di testare a fondo il modello predittivo. Il codice è semplice da comprendere e facilita la sperimentazione grazie alla possibilità di modificare i parametri e l’universo degli asset.
Presentiamo i risultati del backtest della strategia intraday di machine learning supervisionato utilizzando una tecnica di ensemble statistico, il classificatore Random Forest, su un’azione specifica – AREX – nel periodo 2013-2014, addestrata su dati dal 2007 al 2012.
Il codice completo è disponibile alla fine del capitolo. Per eseguirlo serve una versione aggiornata di DataTrader, scaricabile dalla pagina del progetto su GitHub.
Obiettivi Predittivi con il Machine Learning
Iniziamo descrivendo come utilizzare il machine learning supervisionato per prevedere le variazioni direzionali dei prezzi degli asset. Abbiamo già trattato questi metodi nel corso di Machine Learning Supervisionato di TradingQuant.it, ma non li avevamo ancora integrati in un sistema robusto di backtest intraday basato su eventi.
La prima attività consiste nel definire esattamente cosa vogliamo prevedere. Ecco alcune possibilità:
- Direzione: prevedere la variazione direzionale dei rendimenti dell’azione nel prossimo intervallo.
- Tendenza di breve termine: prevedere l’andamento su più intervalli futuri per un set di azioni, su un ampio universo.
- Fattore salita/discesa: identificare le azioni che saliranno oltre una certa soglia e non scenderanno sotto un’altra soglia nei prossimi intervalli (es. 5 minuti).
Esistono molte altre possibilità, ma in questo capitolo ci concentriamo sulla direzione e il fattore salita/discesa per dimostrare le funzionalità intraday.
Lo Sbilanciamento delle Classi
Una delle maggiori difficoltà nel prevedere i rendimenti in finanza quantitativa è lo sbilanciamento delle classi. Prendiamo come esempio il fattore salita/discesa: solo pochi titoli soddisfano i criteri richiesti (es. salita ≥ 2% e discesa ≤ 1% in 5 barre), rispetto a quelli che non li soddisfano.
Se impostiamo questo obiettivo come un problema di classificazione binaria supervisionata – utilizzando barre ritardate come caratteristiche e barre successive come target – ci ritroviamo con molte più barre che non soddisfano il criterio rispetto a quelle che lo rispettano.
Questo porta spesso a modelli che tendono a prevedere sempre la classe più frequente. In tali casi, l’accuratezza apparente (Hit Rate) riflette solo lo sbilanciamento delle classi, e non la reale efficacia del modello.
Matrice di Confusione
Per fortuna possiamo identificare facilmente il problema. Una matrice di confusione mostra chiaramente il numero di veri positivi, veri negativi, falsi positivi (errore di Tipo I) e falsi negativi (errore di Tipo II). Se osserviamo un alto numero di campioni nei falsi negativi e nei veri negativi, siamo probabilmente di fronte a uno sbilanciamento.
Ad esempio, il seguente output per una classificazione binaria mostra un Hit Rate del 58%:
Hit Rate: 0.5885
[[48067 33618]
[ 203 293]]
È evidente che il modello predice quasi sempre la stessa classe, il che spiega l’accuratezza elevata apparente. La maggior parte dei campioni si concentra sulla prima riga.
Esistono diverse tecniche per mitigare questo problema. Non possiamo elencarle tutte qui, ma tra le più comuni troviamo:
- Aumentare il numero di campioni (difficile nei dati finanziari storici).
- Ridurre i campioni della classe dominante per bilanciare le proporzioni.
Un’ulteriore complicazione nei time series è la correlazione seriale: i campioni non sono indipendenti e identicamente distribuiti (i.i.d.), quindi non possiamo semplicemente campionare in modo casuale dalla classe dominante.
Dobbiamo sempre usare una matrice di confusione per verificare che il problema dello sbilanciamento non sia troppo grave. Altrimenti, qualsiasi modello di machine learning che colleghiamo a un motore di trading potrebbe portare a perdite significative.
Modello Predittivo su Dati Storici
In questa sezione costruiamo un modello predittivo usando Scikit-Learn al fine di implementare il backtesta della strategia intraday di machine learning supervisionato. Poiché si tratta di un compito di apprendimento supervisionato, alleniamo il modello su un sottoinsieme dei dati storici. In particolare, usiamo i dati per l’azione statunitense AREX dal tardo 2007 fino alla fine del 2012, anche se il metodo funziona con qualsiasi dato intraday a barre (comprese azioni e forex).
Per addestrare il modello dobbiamo specificare i predittori delle caratteristiche e la risposta. Le caratteristiche, in questo caso, sono i rendimenti al minuto ritardati. La caratteristica p è il rendimento di chiusura della barra p-esima precedente rispetto al rendimento della barra corrente. La risposta è il “fattore su/giù”, come descritto sopra (+1 o -1 per Vero/Falso), oppure la variazione direzionale dei rendimenti nella barra successiva (+1 o -1 per su/giù).
Il codice seguente genera sia il “fattore su/giù” sia la variazione direzionale, ma nella strategia di trading che segue utilizziamo la variazione direzionale come risposta. Possiamo facilmente decommentare una riga nei seguenti frammenti per passare al “fattore su/giù”, ma questo comporta un maggiore squilibrio tra le classi. Ci sono meno istanze in cui l’azione sale di un certo fattore e non scende di un altro, rispetto a una semplice previsione direzionale.
Pickling
Una volta che alleniamo il modello, lo serializziamo. Questo significa che scriviamo su disco l’oggetto Python contenente il modello stesso, insieme al suo set di parametri allenati, in un formato speciale. In questo modo possiamo deserializzare il modello nell’ambiente DataTrader. Questo processo si chiama pickling nell’ecosistema Python.
Il pickling è un meccanismo comune per portare i modelli di machine learning in produzione. Scikit-Learn lo chiama persistenza del modello. Fornisce un modulo chiamato joblib a questo scopo.
Il primo compito nel codice è importare le librerie necessarie, tra cui NumPy, Pandas e Scikit-Learn. In questo esempio alleniamo LinearDiscriminantAnalysis e RandomForestClassifier, ma abbiamo anche importato (e commentato) altri metodi ensemble. Possiamo decommentarli e allenarli se desideriamo altri modelli predittivi. Infine importiamo joblib per la persistenza e confusion_matrix per analizzare lo squilibrio delle classi:
Importazione librerie
import datetime
import numpy as np
import pandas as pd
import joblib
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
La seguente funzione create_up_down_dataframe è piuttosto complessa. Serve a creare la matrice delle caratteristiche X e il vettore delle risposte y, anche se inizialmente le concateniamo nello stesso DataFrame Pandas.
Prende in input il percorso del file CSV, insieme ai ritardi storici dei prezzi al minuto da usare come caratteristiche e ai ritardi futuri da usare come risposte. I parametri up_down_factor e percent_factor controllano il rapporto di quanto un’azione deve salire e non scendere nell’intervallo lookforward_minutes.
Per esempio, se up_down_factor=2.0 e percent_factor=0.01, il DataFrame produrrà una colonna di valori +1 e -1, dove +1 indica le barre per cui, nei successivi lookforward_minutes, i rendimenti superano almeno il 2% e non si riducono oltre l’1%. Cerchiamo quindi istanze in cui l’azione probabilmente aumenta due volte più di quanto diminuisca.
La funzione inizia leggendo il file CSV in Pandas. Imposta i nomi delle colonne e l’indice. Esegue anche il parsing delle date:
def create_up_down_dataframe(csv_filepath, lookback_minutes=30, lookforward_minutes=5, up_down_factor=2.0, percent_factor=0.01, start=None, end=None):
ts = pd.read_csv(
csv_filepath,
names=["Timestamp", "Open", "Low", "High", "Close", "Volume", "OpenInterest"],
index_col="Timestamp", parse_dates=True
)
# Filtro sulle date di inizio/fine
if start is not None:
ts = ts[ts.index >= start]
if end is not None:
ts = ts[ts.index <= end]
# Elimina le colonne non essenziali
ts.drop(["Open", "Low", "High", "Volume", "OpenInterest"], axis=1, inplace=True)
# Crea i ritardi lookback e lookforward
for i in range(0, lookback_minutes):
ts["Lookback%s" % str(i+1)] = ts["Close"].shift(i+1)
for i in range(0, lookforward_minutes):
ts["Lookforward%s" % str(i+1)] = ts["Close"].shift(-(i+1))
ts.dropna(inplace=True)
# Convertiamo in rendimenti percentuali
ts["Lookback0"] = ts["Close"].pct_change()*100.0
for i in range(0, lookback_minutes):
ts["Lookback%s" % str(i+1)] = ts["Lookback%s" % str(i+1)].pct_change()*100.0
for i in range(0, lookforward_minutes):
ts["Lookforward%s" % str(i+1)] = ts["Lookforward%s" % str(i+1)].pct_change()*100.0
ts.dropna(inplace=True)
Calcolo fattore up/down
Il codice successivo calcola il “fattore up/down”. Crea una lista di colonne True/False per ogni lag storico o futuro.
Le colonne “down” sono iterate e combinate con AND bit a bit (&) per generare una colonna finale True solo quando tutte le colonne non sono scese sotto la soglia down. Le colonne “up” sono combinate con OR bit a bit (|) per creare una colonna True quando almeno una supera la soglia up. Queste due colonne sono poi combinate con AND bit a bit per generare una colonna finale True quando entrambe le condizioni sono soddisfatte.
Dato che si usa Python con operatori True/False, bisogna convertire in +1 e -1, che le ultime due righe fanno.
Nota che nel codice il “fattore up/down” è commentato a favore del cambiamento direzionale, ma mantiene lo stesso nome di colonna UpDown. Se si vuole usare il “fattore up/down” come risposta, bisogna decommentare la riga con ts["UpDown"] = down_tot & up_tot e commentare la linea sottostante:
# Determina se il titolo è salito almeno di
# ’up_down_factor’ x ’percent_factor’ e non è sceso più di
# allora ’percent_factor’
up = up_down_factor*percent_factor
down = percent_factor
# Crea la lista di voci True/False per ogni data
# per verificare se la logica up/down è vera
down_cols = [ts["Lookforward%s" % str(i+1)] > -down for i in range(0, lookforward_minutes)]
up_cols = [ts["Lookforward%s" % str(i+1)] > up for i in range(0, lookforward_minutes)]
# Esegui l’and bit a bit, così come l’or bit a bit
# per la logica down e up
down_tot = down_cols[0]
for c in down_cols[1:]:
down_tot = down_tot & c
up_tot = up_cols[0]
for c in up_cols[1:]:
up_tot = up_tot | c
ts["UpDown"] = np.sign(ts["Lookforward1"])
# Converti True/False in 1 e 0
ts["UpDown"] = ts["UpDown"].astype(int)
ts["UpDown"].replace(to_replace=0, value=-1, inplace=True)
return ts
Esecuzione dell’addestramento
Questa funzione esegue il lavoro di preparazione dei dati dello script. Nella funzione __main__ richiamiamo la funzione sopra per i dati AREX.
n_estimators controlla il numero di alberi decisionali da usare nel RandomForestClassifier, mentre n_jobs controlla il numero di core della CPU da usare per l’addestramento.
Assicuriamoci di cambiare il nostro percorso da csv_filepath = "/path/to/your/AREX.csv" al percorso in cui risiedono i nostri dati AREX (o altri) prima di eseguire questo script.
if __name__ == "__main__":
random_state = 42
n_estimators = 400
n_jobs = 1
csv_filepath = "/path/to/your/AREX.csv"
lookback_minutes = 30
lookforward_minutes = 5
print("Importing and creating CSV DataFrame...")
start_date = datetime.datetime(2007, 11, 8)
end_date = datetime.datetime(2012, 12, 31)
ts = create_up_down_dataframe(csv_filepath, lookback_minutes=lookback_minutes, lookforward_minutes=lookforward_minutes, start=start_date, end=end_date)
Il codice seguente utilizza il DataFrame Pandas generato sopra per creare la matrice delle feature X e il vettore di risposta y. In questo caso utilizziamo solo i primi cinque ritardi precedenti, anche se ne abbiamo a disposizione trenta nella generazione iniziale dei dati.
Una volta che abbiamo formattato i dati nelle strutture X e y, creiamo una suddivisione tra addestramento e test, dove il set di test equivale al 30% dei dati. Notiamo che nello sviluppo finale del modello non dobbiamo suddividere i dati in questo modo: dobbiamo invece utilizzare tutti i dati fino al 2012 per addestrare il modello, e usare i dati rimanenti del 2013/2014 per validare la strategia di trading fuori campione.
# Usa i primi cinque ritardi giornalieri dei prezzi di chiusura AREX
print("Preprocessing data...")
X = ts[
[
"Lookback%s" % str(i)
for i in range(0, 5)
]
]
y = ts["UpDown"]
# Usa la suddivisione training-testing con il 70% dei dati nel
# training e il restante 30% dei dati nel testing
print("Creating train/test split of data...")
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=random_state
)
Addestramento del modello
In questa sezione il modello viene effettivamente adattato ai dati. Il parametro importante è max_depth, che controlla la profondità massima degli alberi cresciuti nella Random Forest. Esso controlla il compromesso bias-varianza del modello. Un max_depth più piccolo avrà una capacità predittiva ridotta, ma produrrà un file di dimensioni molto più piccole e verrà eseguito molto più rapidamente in DataTrader.
Di conseguenza, un max_depth più grande potrà potenzialmente sovradattare i dati di addestramento, avrà una dimensione di file significativa (il valore predefinito porta a un modello di 4,1 Gb di dimensione!) e verrà eseguito lentamente in DataTrader.
Il tasso di successo e la matrice di confusione per il set di test vengono anche forniti qui se la divisione training/test è scelta come sopra. Dobbiamo anche modificare il percorso verso i dati nell’applicazione di joblib.
print("Fitting classifier model...")
model = RandomForestClassifier(n_estimators=n_estimators, n_jobs=n_jobs, random_state=random_state, max_depth=10)
model.fit(X_train, y_train)
print("Outputting metrics...")
print("Hit-Rate: %s" % model.score(X_test, y_test))
print("%s\n" % confusion_matrix(model.predict(X_test), y_test))
print("Pickling model...")
joblib.dump(model,"../_out/ml_model_rf.pkl")
Questo conclude lo script di generazione del modello. Il file del modello serializzato (pickled) è memorizzato in ml_model_rf.pkl e sarà utilizzato nel seguente oggetto Strategy di DataTrader.
Strategia Intraday di machine learning
Ora che il modello predittivo è stato correttamente serializzato con joblib, vediamo come utilizzare il modello predittivo “online” all’interno di una strategia intraday di machine learning supervisionato implementata con il framework DataTrader.
La strategia in sé è relativamente semplice. Ogni barra ricevuta tramite l’evento viene usata per formare un array a lunghezza ritardata mobile dei prezzi di chiusura delle barre precedenti. Questo viene poi trasformato in un insieme di rendimenti e moltiplicato per 100, come nella fase di fitting del modello predittivo.
Per facilitare la comprensione della procedura, la strategia è stata impostata per andare solo long ed uscire. Non esegue posizioni short e uscita, anche se questa è una modifica semplice se si desidera.
Per ogni barra viene chiamato il metodo predict del modello, che restituisce +1 o -1 a seconda della direzione prevista per la barra successiva. Se la strategia non è investita e riceve un +1, allora apre una posizione long di 10.000 unità di AREX. Se la strategia è investita e riceve un -1, allora chiude la posizione di 10.000 unità.
NumPy e Pandas sono entrambi usati all’interno della classe, così come joblib per deserializzare (unpickling) il modello predittivo. Inoltre, vengono importati i soliti oggetti DataTrader per le classi Strategy:
# intraday_ml_strategy.py
import numpy as np
import pandas as pd
import joblib
from datatrader.price_parser import PriceParser
from datatrader.event import (SignalEvent, EventType)
from datatrader.strategy.base import AbstractStrategy
Inizializzazione della classe
L’inizializzazione della classe che implementa la strategia intraday di machine learning supervisionato è relativamente semplice. Prendiamo il percorso del file pickle del modello tramite model_pickle_file come parametro di inizializzazione, insieme al numero di ritardi a livello di barre al minuto da usare per prevedere la direzione della prossima barra, tramite lags.
Conserviamo i prezzi correnti in cur_prices, che ha un elemento in più rispetto all’array dei rendimenti correnti, cur_returns, poiché per calcolare n rendimenti servono n + 1 elementi di prezzo. Impostiamo la quantità qty a 10.000 in questo caso, poiché abbiamo 500.000 USD di capitale. L’oggetto model contiene il modello predittivo deserializzato (unpickled) da Scikit-Learn:
class IntradayMachineLearningPredictionStrategy(AbstractStrategy):
"""
Richiede:
tickers – L'elenco dei simboli ticker
events_queue – Un riferimento alla coda degli eventi di sistema
"""
def __init__(self, tickers, events_queue, model_pickle_file, lags=5):
self.tickers = tickers
self.events_queue = events_queue
self.model_pickle_file = model_pickle_file
self.lags = lags
self.invested = False
self.cur_prices = np.zeros(self.lags+1)
self.cur_returns = np.zeros(self.lags)
self.minutes = 0
self.qty = 10000
self.model = joblib.load(model_pickle_file)
Calcolo dei Rendimenti
Il metodo _update_current_returns serve per generare l’array scorrevole delle lunghezze di ritardo dei rendimenti dei prezzi di chiusura di AREX. Iniziamo iterando all’indietro attraverso l’array dei prezzi correnti e sposta i prezzi di uno, aggiungendo il nuovo prezzo più recente.
Gli informatici tra noi riconosceranno questo comportamento come ben rappresentato da una coda a doppia estremità (deque). Python contiene un’implementazione di questo tipo nella libreria collections. Per semplicità, usiamo array NumPy in questo esempio.
Una volta generato l’array dei prezzi correnti, calcoliamo la lista dei rendimenti, ma solo quando tutti gli elementi sono stati popolati nella lista (cioè dopo lags+1):
def _update_current_returns(self, event):
"""
Aggiorniamo l'array delle "features" dei rendimenti correnti utilizzato
dal modello di machine learning per la previsione.
"""
# Regoliamo il vettore delle feature per spostare tutti i ritardi di uno
# e poi ricalcoliamo i rendimenti
for i, f in reversed(list(enumerate(self.cur_prices))):
if i > 0:
self.cur_prices[i] = self.cur_prices[i - 1]
else:
self.cur_prices[i] = event.close_price / float(
PriceParser.PRICE_MULTIPLIER
)
if self.minutes > (self.lags + 1):
for i in range(0, self.lags):
self.cur_returns[i] = ((self.cur_prices[i] / self.cur_prices[i + 1]) - 1.0) * 100.0
Calcolo dei segnali
Come con tutte le sottoclassi di Strategy in DataTrader, la generazione del segnale per la strategia intraday di machine learning supervisionato avviene nel metodo calculate_signals. Per prima cosa, aggiorniamo i ritorni correnti alla ricezione di una nuova barra di dati di mercato. Se sono passati abbastanza minuti (lags+2), allora il modello inizia a fare previsioni basate sui dati correnti dei ritorni.
Notiamo che nelle versioni più recenti di Scikit-Learn è necessario trasformare gli array monodimensionali in array bidimensionali contenenti una singola riga, altrimenti compare un avviso di deprecazione. Questo spiega la chiamata al metodo reshape((1, -1)). Infine, poiché model.predict restituisce un array contenente uno scalare singolo piuttosto che lo scalare stesso, dobbiamo usare l’operatore di indicizzazione ([0]) per estrarre il valore.
La logica restante si occupa di entrare in posizione long o uscire, a seconda che la strategia sia già investita e se la previsione sia +1 oppure -1. Come al solito, inviamo oggetti SignalEvent alla events_queue per essere utilizzati dall’oggetto Portfolio.
def calculate_signals(self, event):
"""
Calcola la strategia di previsione del machine learning intraday.
"""
if event.type == EventType.BAR:
self._update_current_returns(event)
self.minutes += 1
# Allow enough time to pass to populate the
# returns feature vector
if self.minutes > (self.lags + 2):
pred = self.model.predict(self.cur_returns.reshape((1, -1)))[0]
# Long only strategy
if not self.invested and pred == 1:
print("LONG: %s" % event.time)
self.events_queue.put(SignalEvent(self.tickers[0], "BOT", self.qty))
self.invested = True
if self.invested and pred == -1:
print("CLOSING LONG: %s" % event.time)
self.events_queue.put(SignalEvent(self.tickers[0], "SLD", self.qty))
self.invested = False
Sfortunatamente, per i modelli più complessi, la chiamata a model.predict può essere estremamente lenta. Per i modelli più semplici con parametri minimi (ad esempio, la regressione lineare), la chiamata è veloce. Sulla workstation desktop utilizzata qui per generare i risultati, siamo riusciti a ottenere circa 5.000 barre al secondo per i modelli semplici.
Modelli Complessi
Per modelli più complessi, come i classificatori Random Forest con molti alberi profondamente sviluppati, questa velocità di previsione può diminuire sostanzialmente, spesso fino a tre ordini di grandezza. Per l’ensemble Random Forest in particolare, il modello iniziale generato in questo esempio ha prodotto un file pickle di 4,1Gb, che supera la capacità di RAM di alcuni PC più datati. Quindi, il metodo è costretto a usare il disco durante la previsione di nuovi punti dati, il che può ridurre pesantemente le prestazioni.
Uno degli obiettivi dell’ottimizzazione di un modello consiste nell’assicurarci che sia possibile generare effettivamente delle previsioni in un arco di tempo ragionevole. Nel caso del classificatore Random Forest, abbiamo dovuto sperimentare con la profondità massima dell’albero per ridurre la dimensione finale del file pickle ma ottenere comunque prestazioni di previsione ragionevoli. Il modello finale rappresenta un compromesso tra accuratezza della previsione e velocità di esecuzione del backtest, che ha funzionato a circa 60 barre al secondo nell’esempio seguente.
Script di Backtest con DataTrader
Ora che abbiamo sviluppato la classe Strategy, dobbiamo eseguire il backtest della strategia intraday di machine learning supervisionato. Forniamo qui sotto questo codice, all’interno del file intraday_ml_backtest.py. È molto simile ad altre implementazioni di DataTrader.
Le principali differenze consistono nell’importazione di un nuovo gestore prezzi, IQFeedIntradayCsvBarPriceHandler, al posto di uno progettato per i dati giornalieri di Yahoo Finance, così come nel parametro periods per la classe TearsheetStatistics, che è stato impostato su 252 × 6.5 × 60 = 98280. Questo ci assicura che il Rapporto di Sharpe calcolato sia corretto rispetto al numero di periodi utilizzati:
# intraday_ml_backtest.py
import datetime
from datatrader import settings
from datatrader.compat import queue
from datatrader.price_parser import PriceParser
from datatrader.price_handler.iq_feed_intraday_csv_bar import IQFeedIntradayCsvBarPriceHandler
from datatrader.strategy.base import Strategies
from datatrader.position_sizer.naive import NaivePositionSizer
from datatrader.risk_manager.example import ExampleRiskManager
from datatrader.portfolio_handler import PortfolioHandler
from datatrader.compliance.example import ExampleCompliance
from datatrader.execution_handler.ib_simulated import IBSimulatedExecutionHandler
from datatrader.statistics.tearsheet import TearsheetStatistics
from datatrader.trading_session import TradingSession
from intraday_ml_strategy import IntradayMachineLearningPredictionStrategy
def run(config, testing, tickers, filename):
# Imposta le variabili necessarie per il backtest
events_queue = queue.Queue()
csv_dir = config.CSV_DATA_DIR
initial_equity = PriceParser.parse(500000.00)
# Utilizza il gestore dei prezzi intraday DTN IQFeed (dati da file CSV)
start_date = datetime.datetime(2013, 1, 1)
end_date = datetime.datetime(2014, 3, 11)
price_handler = IQFeedIntradayCsvBarPriceHandler(csv_dir, events_queue, tickers, start_date=start_date)
# Utilizza la strategia di previsione intraday basata su apprendimento automatico
model_pickle_file = filename
strategy = IntradayMachineLearningPredictionStrategy(tickers, events_queue, model_pickle_file, lags=5)
strategy = Strategies(strategy)
# Utilizza il Position Sizer Naive (le quantità suggerite vengono seguite)
position_sizer = NaivePositionSizer()
# Utilizza un esempio di gestore del rischio
risk_manager = ExampleRiskManager()
# Utilizza il gestore di portafoglio predefinito
portfolio_handler = PortfolioHandler(initial_equity, events_queue, price_handler, position_sizer, risk_manager)
# Utilizza il componente di conformità di esempio
compliance = ExampleCompliance(config)
# Utilizza un simulatore di esecuzione IB
execution_handler = IBSimulatedExecutionHandler(events_queue, price_handler, compliance)
# Utilizza le statistiche di tipo Tearsheet
title = "Intraday AREX Machine Learning Prediction Strategy"
statistics = TearsheetStatistics(config, portfolio_handler, periods=int(252 * 6.5 * 60)) # Periodi in minuti
# Settaggio del backtest
backtest = TradingSession(
config, strategy, tickers,
initial_equity, start_date, end_date, events_queue,
price_handler=price_handler,
portfolio_handler=portfolio_handler,
compliance=compliance,
position_sizer=position_sizer,
execution_handler=execution_handler,
risk_manager=risk_manager,
statistics=statistics,
sentiment_handler=None,
title=title, benchmark=tickers[0]
)
results = backtest.start_trading(testing=testing)
statistics.save(filename)
return results
if __name__ == "__main__":
# Dati di configurazione
testing = False
config = settings.from_file(
settings.DEFAULT_CONFIG_FILENAME, testing
)
tickers = ["AREX"]
filename = "../data/ml_model_rf.pkl"
run(config, testing, tickers, filename)
$ python intraday_ml_backtest.py
Risultati
Presentiamo qui due backtest della strategia intraday di machine learning supervisionato, entrambi coprono il periodo dal 1° gennaio 2013 all’11 marzo 2014, cioè poco più di un anno. Nel primo test addestriamo un Analizzatore Discriminante Lineare con le impostazioni predefinite di Scikit-Learn, mentre nel secondo addestriamo un modello a insieme Random Forest con una profondità massima degli alberi pari a dieci.
Alleniamo entrambi i modelli sui dati AREX dall’8 novembre 2007 al 31 dicembre 2012. Utilizziamo entrambi i backtest con il rispettivo modello “out of sample”, cioè su dati che i classificatori non hanno visto durante l’addestramento. Inoltre calcoliamo entrambi i backtest al netto delle commissioni standard di Interactive Brokers USA. I test non includono slippage, impatto di mercato o effetto dello spread – tutti elementi che probabilmente avranno un impatto negativo sul CAGR.
Analizzatore Discriminante Lineare
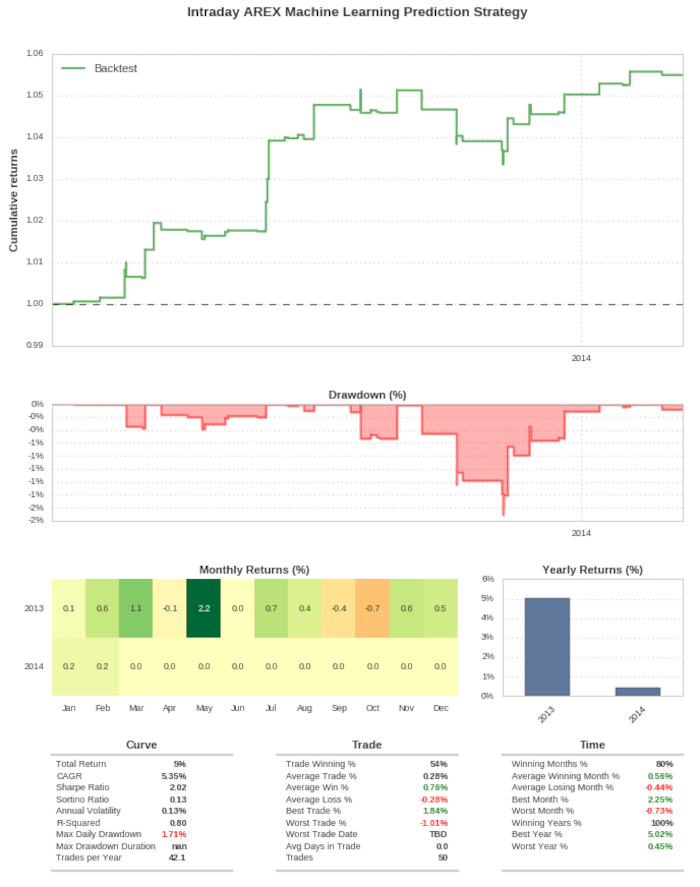
Vediamo la scheda riassuntiva della strategia basata su Analizzatore Discriminante Lineare, Essa mostra un Sharpe Ratio out-of-sample pari a 2,02, valore superiore a quello che troviamo spesso in un modello giornaliero, come ci si aspetta da modelli ad alta frequenza. Con un blocco di transazione di 10.000 azioni, mostra un CAGR del 5,35%, con un drawdown massimo giornaliero dell’1,71%. Il drawdown ridotto è conseguenza dei periodi di detenzione molto brevi della strategia, che sono di solito nell’ordine di minuti. La curva di equity è generalmente crescente anche se c’è un periodo in cui la strategia resta sott’acqua per tre mesi alla fine del 2013.
Random Forest
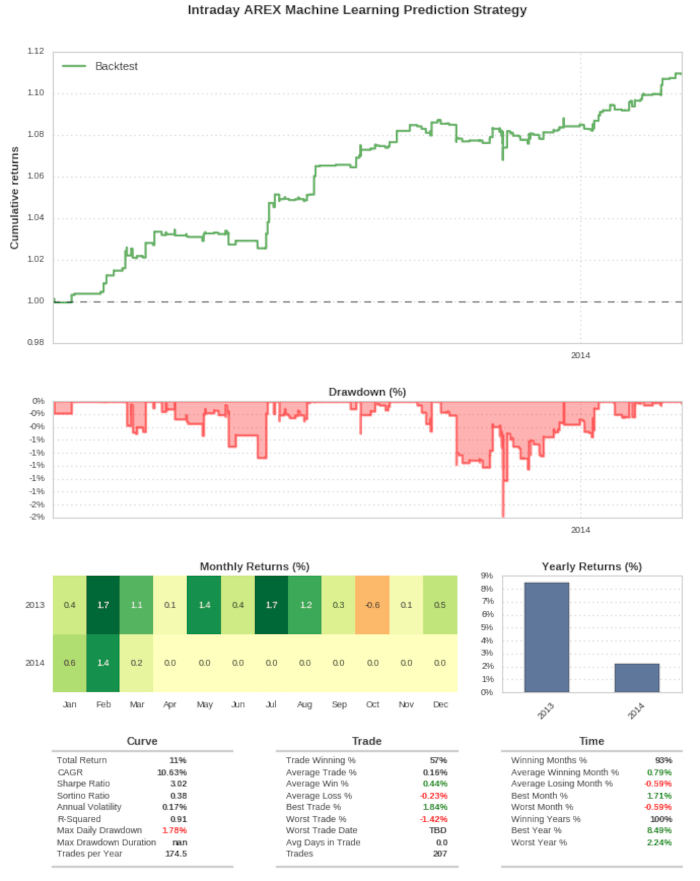
Di seguito il report delle performance della strategia con il Random Forest. La strategia registra uno Sharpe Ratio out-of-sample di 3,02, su un CAGR del 10,63%. Notiamo che calcolare un CAGR su circa un anno di dati è fuorviante, poiché sarà quasi uguale al rendimento totale.
Lo Sharpe Ratio è più alto rispetto a quello della LDA poiché i rendimenti sono aumentati, ma i drawdown sono rimasti approssimativamente gli stessi. Anche la curva di equity appare visivamente più coerente. Nonostante ciò, rimane comunque in negativo per gli ultimi tre mesi del 2013 e inizia a recuperare solo all’inizio del 2014.
Conclusioni
Dobbiamo fare ancora molto lavoro per trasformare questa strategia intraday di machine learning supervisionato in una strategia efficace da implementare in produzione. Il primo passo consiste nel replicare questo modello su decine o centinaia di titoli azionari (a seconda del capitale disponibile!) come metodo per tentare di generare molte “scommesse” non correlate su, ad esempio, settori separati del mercato.
Inoltre, dobbiamo condurre uno studio più robusto sugli iperparametri per molti dei classificatori. Questo ottimizzerà il compromesso bias-varianza nei modelli. In una certa misura, controlliamo questo aspetto tramite la profondità massima dell’albero nel classificatore Random Forest.
Per portare questo sistema da una simulazione storica a un modello produttivo funzionante in modo coerente, dobbiamo considerare slippage, impatto di mercato, volume medio giornaliero delle azioni scambiate e commissioni più realistiche.
Eseguire strategie a frequenza intraday è chiaramente molto più difficile rispetto a quelle giornaliere. Questo è il “prezzo da pagare” per ottenere Sharpe ratio più elevati e, di conseguenza, strategie con significatività statistica migliorata.
Codice Completo
Il codice completo presentato in questo articolo, basato sul framework di trading quantitativo event-driven DataTrader, è disponibile nel seguente repository GitHub: https://github.com/tradingquant-it/DataTrader.”